大數(shù)據(jù)存儲(chǔ)與處理 Hive與Pig的數(shù)據(jù)處理與存儲(chǔ)服務(wù)探析
隨著大數(shù)據(jù)技術(shù)的飛速發(fā)展,Hive與Pig作為Hadoop生態(tài)系統(tǒng)中的重要組件,為海量數(shù)據(jù)的存儲(chǔ)與處理提供了高效、可擴(kuò)展的解決方案。本文將從數(shù)據(jù)處理和存儲(chǔ)服務(wù)的角度,深入探討Hive與Pig的核心功能、應(yīng)用場(chǎng)景及其互補(bǔ)關(guān)系。
1. Hive:基于SQL的數(shù)據(jù)倉(cāng)庫(kù)工具
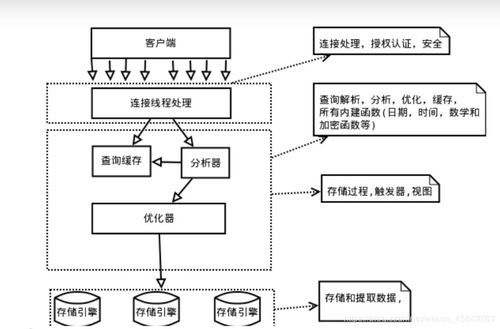
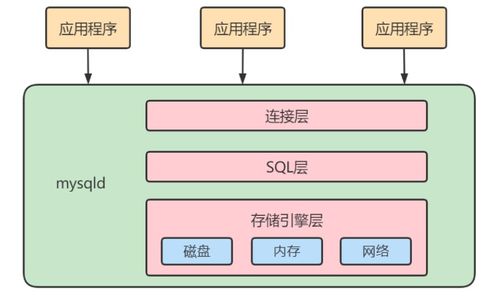
Hive是一個(gè)構(gòu)建在Hadoop之上的數(shù)據(jù)倉(cāng)庫(kù)工具,它允許用戶使用類似于SQL的HiveQL語言來查詢和管理存儲(chǔ)在HDFS(Hadoop分布式文件系統(tǒng))中的大規(guī)模數(shù)據(jù)集。其主要特點(diǎn)包括:
- 數(shù)據(jù)存儲(chǔ):Hive將數(shù)據(jù)以表的形式組織,支持結(jié)構(gòu)化數(shù)據(jù)的存儲(chǔ),數(shù)據(jù)實(shí)際存儲(chǔ)在HDFS中,元數(shù)據(jù)則保存在關(guān)系型數(shù)據(jù)庫(kù)(如MySQL)中。
- 數(shù)據(jù)處理:通過HiveQL,用戶可以執(zhí)行數(shù)據(jù)查詢、聚合、過濾等操作,Hive會(huì)自動(dòng)將查詢轉(zhuǎn)換為MapReduce任務(wù)在Hadoop集群上執(zhí)行。
- 適用場(chǎng)景:適用于離線批處理、數(shù)據(jù)倉(cāng)庫(kù)構(gòu)建、歷史數(shù)據(jù)分析等需要復(fù)雜查詢和聚合的場(chǎng)景。
2. Pig:數(shù)據(jù)流處理平臺(tái)
Pig是一個(gè)用于大規(guī)模數(shù)據(jù)分析的平臺(tái),它提供了一種名為Pig Latin的高級(jí)腳本語言,專注于數(shù)據(jù)流的處理。其核心優(yōu)勢(shì)在于:
- 數(shù)據(jù)模型:Pig基于嵌套數(shù)據(jù)模型,支持復(fù)雜數(shù)據(jù)類型(如Map、Tuple、Bag),更適合處理半結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù)。
- 數(shù)據(jù)處理流程:Pig Latin腳本描述了數(shù)據(jù)從加載、轉(zhuǎn)換到存儲(chǔ)的完整流程,Pig會(huì)將其編譯為一系列MapReduce任務(wù)執(zhí)行。
- 適用場(chǎng)景:適用于ETL(提取、轉(zhuǎn)換、加載)任務(wù)、數(shù)據(jù)流水線處理、迭代計(jì)算等需要靈活數(shù)據(jù)處理的場(chǎng)景。
3. Hive與Pig的互補(bǔ)性
盡管Hive和Pig都服務(wù)于大數(shù)據(jù)處理,但它們?cè)谠O(shè)計(jì)哲學(xué)和應(yīng)用層面各有側(cè)重:
- 語言差異:Hive采用類SQL的聲明式語言,更適合熟悉SQL的數(shù)據(jù)分析師;Pig使用過程式的腳本語言,更適合描述復(fù)雜的數(shù)據(jù)流水線。
- 性能特點(diǎn):Hive在復(fù)雜查詢和聚合操作上優(yōu)化較好;Pig在數(shù)據(jù)流水線和多步轉(zhuǎn)換任務(wù)中表現(xiàn)更高效。
- 協(xié)作使用:在實(shí)際項(xiàng)目中,Hive常用于構(gòu)建數(shù)據(jù)倉(cāng)庫(kù)和即席查詢,而Pig用于數(shù)據(jù)清洗和預(yù)處理,兩者可以協(xié)同工作,提升整體數(shù)據(jù)處理效率。
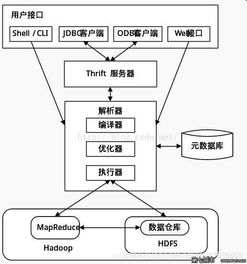
4. 存儲(chǔ)與處理的集成服務(wù)
在大數(shù)據(jù)架構(gòu)中,Hive和Pig通常與HDFS、YARN等組件緊密集成,形成完整的數(shù)據(jù)處理與存儲(chǔ)服務(wù)鏈:
- 存儲(chǔ)層:HDFS提供高容錯(cuò)、高吞吐量的分布式存儲(chǔ),為Hive表和Pig數(shù)據(jù)源提供底層支持。
- 資源管理:YARN負(fù)責(zé)集群資源調(diào)度,確保Hive和Pig任務(wù)高效執(zhí)行。
- 數(shù)據(jù)交互:Hive和Pig可以共享HDFS中的數(shù)據(jù),并通過HCatalog等工具實(shí)現(xiàn)元數(shù)據(jù)互通,簡(jiǎn)化數(shù)據(jù)管理流程。
5. 與展望
Hive和Pig作為大數(shù)據(jù)處理的關(guān)鍵工具,分別從聲明式查詢和數(shù)據(jù)流處理的角度,降低了大規(guī)模數(shù)據(jù)處理的復(fù)雜度。隨著云計(jì)算和實(shí)時(shí)處理技術(shù)的發(fā)展,Hive on Spark、Pig on Tez等新架構(gòu)進(jìn)一步提升了處理性能。它們將繼續(xù)與新興技術(shù)融合,為企業(yè)在數(shù)據(jù)存儲(chǔ)、處理與分析方面提供更強(qiáng)大的服務(wù)支持。
最新產(chǎn)品